Workflow SDKとNitro v3: durable backendがアプリ実行環境へ近づく
1回のHTTP requestに収まらない処理には、queue、retry、状態管理、監視が必要になる。Workflow SDKのNitro v3統合は、そのdurable executionをNitro/Nuxtのコードに近づける。
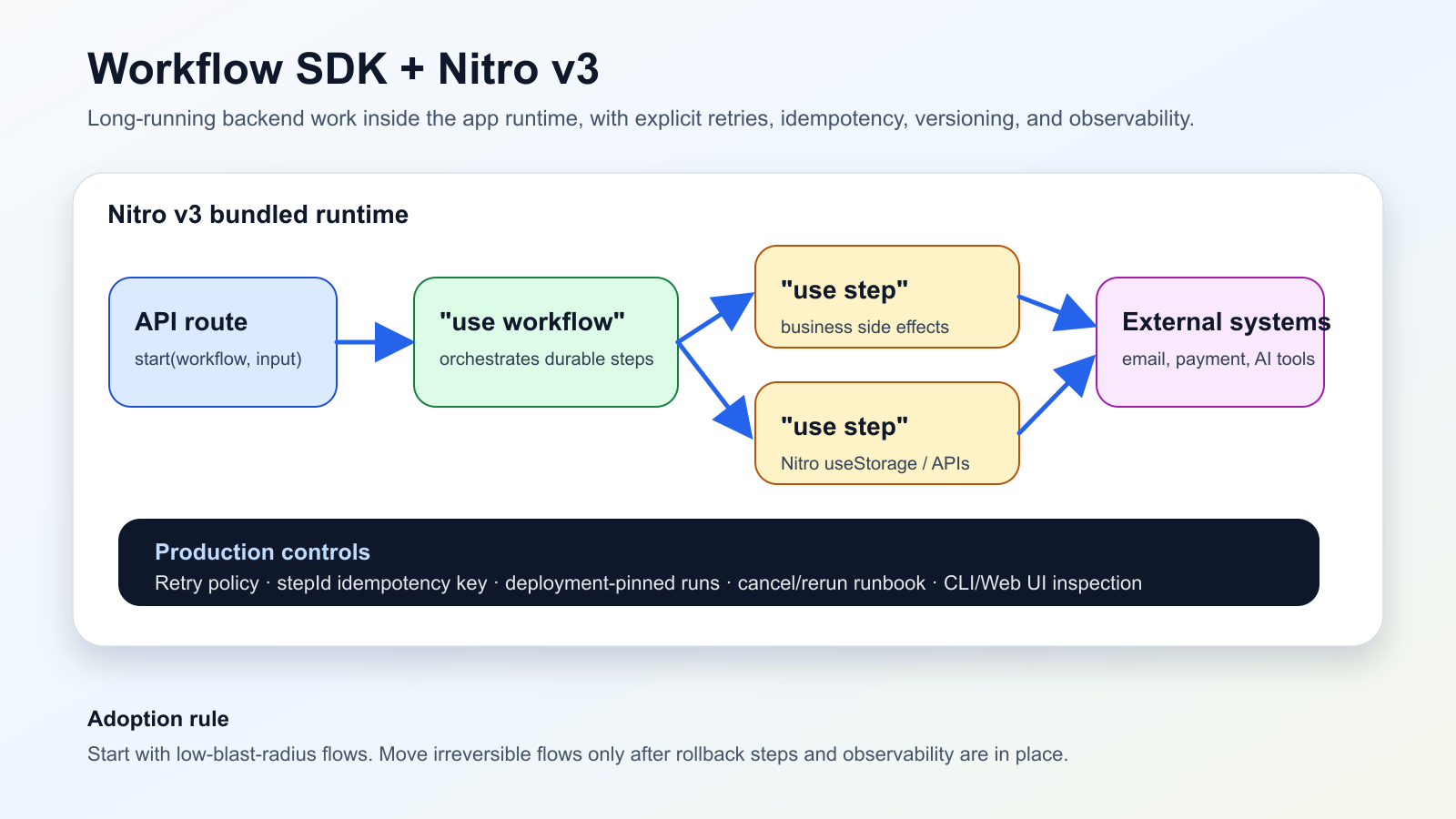
何が起きたか
Vercelは2026年6月13日、Workflow SDKのNitro v3ネイティブ統合がbetaになったと発表した。stepはアプリと同じbundled runtimeで実行され、workflow routeはNitro buildの一部になり、useStorageのようなserver-side APIを"use step"内で直接使える。
なぜ重要か
Nuxt/Nitroチームにとって、これは長時間実行処理の置き場所を変える。API routeがworkflowを開始し、"use workflow"が orchestration を担い、stepがretry可能なside effectを実行する。別workerを作る前に、アプリruntime内でdurable backendを設計できる。
コミュニティのシグナル
ただし便利さは責任も増やす。外部API書き込みにはidempotency keyが必要で、FatalErrorとRetryableErrorを使い分け、実行中のrunが開始deploymentに固定されることをrunbookに書く必要がある。
開発と運用への影響
導入は段階的に行うべきです。オンボーディングメール、レポート生成、遅延通知、承認付きAI agent flowのように観測しやすく巻き戻しやすい処理から始め、決済や在庫のような不可逆処理はrollback stepとrunbookを揃えてから移行します。
実務チェックリスト
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
リスクと反論
この統合はbetaであり、すべてのjobをworkflowへ置き換える理由にはなりません。短いcache更新や単純なwebhook forwardingは通常のrequest/responseや小さなqueueで十分な場合があります。便利な同一runtimeアクセスは、retryしてよいコードとしてはいけないコードの境界を曖昧にしない範囲で使うべきです。
出典
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?