Workflow SDK y Nitro v3: los backends durables entran en el runtime de la app
Cuando un flujo no cabe en una peticion HTTP, aparecen colas, workers, tablas de estado y retries. Workflow SDK para Nitro v3 intenta llevar esa orquestacion al mismo runtime donde vive la aplicacion.
Que ha pasado
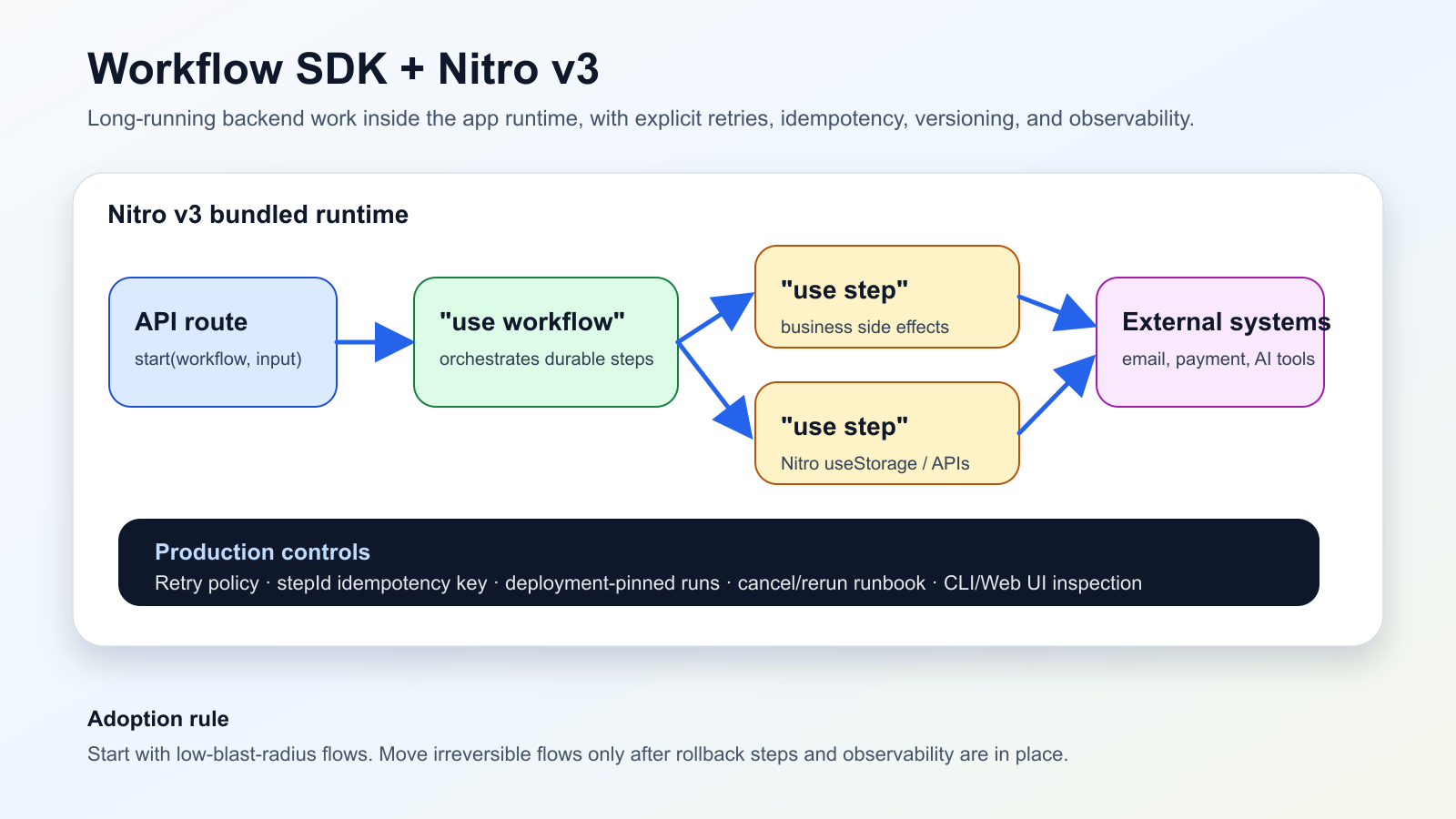
Vercel anuncio el 13 de junio de 2026 que Workflow SDK ya tiene una integracion nativa con Nitro v3 en beta. Los steps se ejecutan dentro del mismo runtime empaquetado de la app, las rutas de workflow forman parte del build de Nitro y APIs como useStorage pueden usarse dentro de funciones "use step".
Por que importa
Para equipos Nuxt/Nitro, esto cambia donde se colocan los procesos largos. Ya no siempre hace falta crear primero un worker separado: una ruta API puede iniciar el workflow, el orchestrator mantiene el estado durable y cada step ejecuta efectos de negocio con retry y observabilidad.
Senales de la comunidad
La parte critica no es escribir menos codigo, sino escribir mejores limites. Las operaciones externas necesitan idempotency keys, los errores no recuperables deben separarse con FatalError y los runs en curso deben tratarse como trabajo ligado a una version concreta del deployment.
Impacto en desarrollo y operaciones
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Checklist practica
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Riesgos y objeciones
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Fuentes
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?