Workflow SDK et Nitro v3 : les backends durables entrent dans le runtime applicatif
Les vrais couts backend apparaissent souvent quand un traitement doit attendre, reprendre ou etre rejoue. L’integration Nitro v3 du Workflow SDK rapproche ces flux du code applicatif.
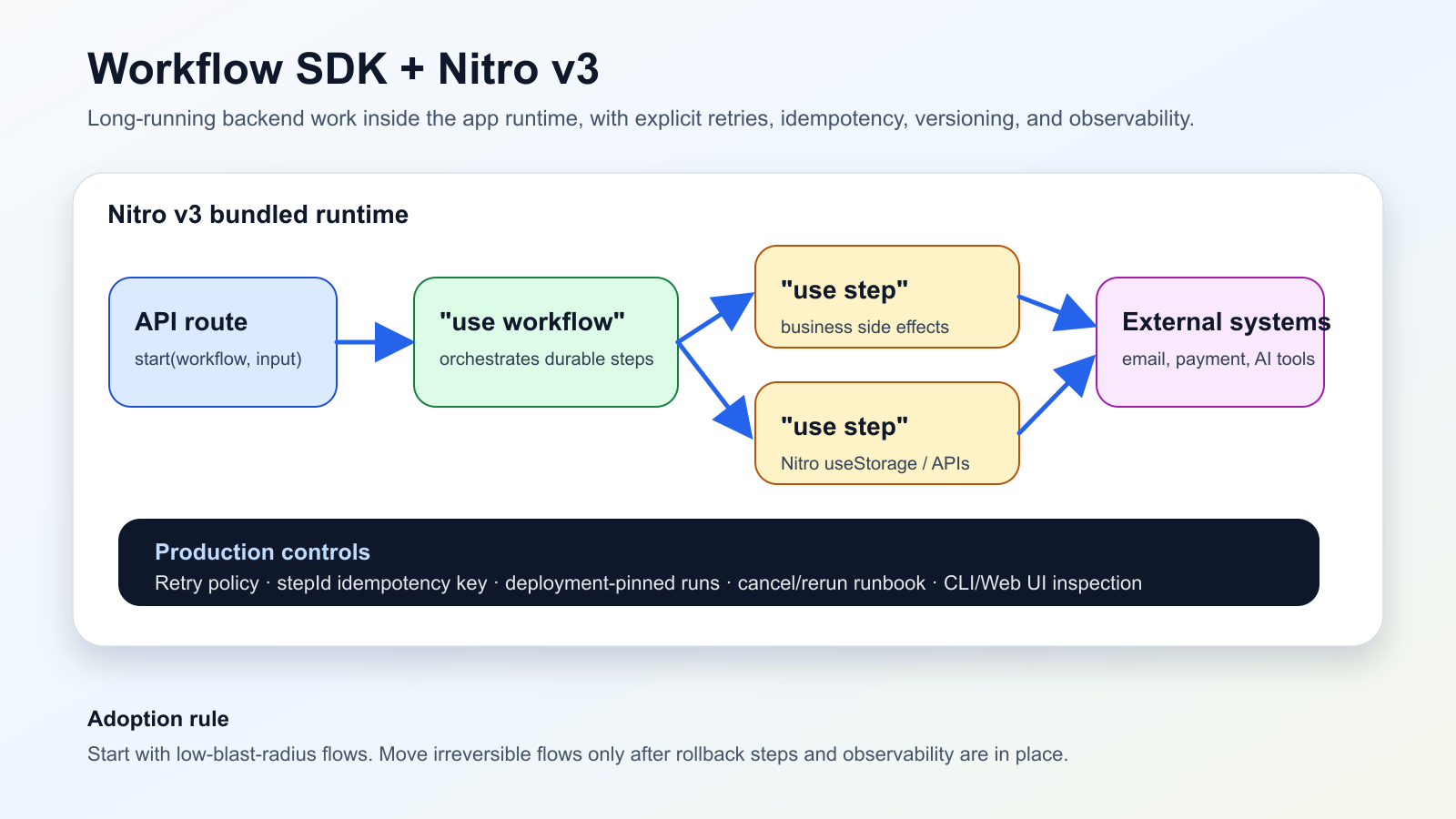
Ce qui a change
Le 13 juin 2026, Vercel a annonce que Workflow SDK s’integre nativement a Nitro v3 en beta. Les steps s’executent dans le meme runtime bundle que l’application, les routes de workflow font partie du build Nitro, et des APIs serveur comme useStorage deviennent accessibles dans les fonctions "use step".
Pourquoi cela compte
Pour les equipes Nuxt et Nitro, cela rapproche les traitements longs du code applicatif. Une route API peut declencher le workflow, la fonction "use workflow" orchestre les etapes, et les steps executent les effets de bord avec reprise et inspection.
Signaux de la communaute
La contrepartie est operationnelle. Il faut distinguer les erreurs retryables des erreurs fatales, ajouter des cles d’idempotence aux appels externes, comprendre que les runs restent attaches au deployment de depart, et rendre les executions visibles dans la CLI ou l’interface Web.
Impact developpement et operations
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Checklist pratique
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Risques et objections
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Sources
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?