Workflow SDK dan Nitro v3: backend durable masuk ke runtime aplikasi
Pekerjaan backend yang tidak selesai dalam satu request biasanya membutuhkan queue, retry, tabel status, dan monitoring. Integrasi Workflow SDK dengan Nitro v3 mencoba membuat pola itu terasa seperti kode aplikasi biasa.
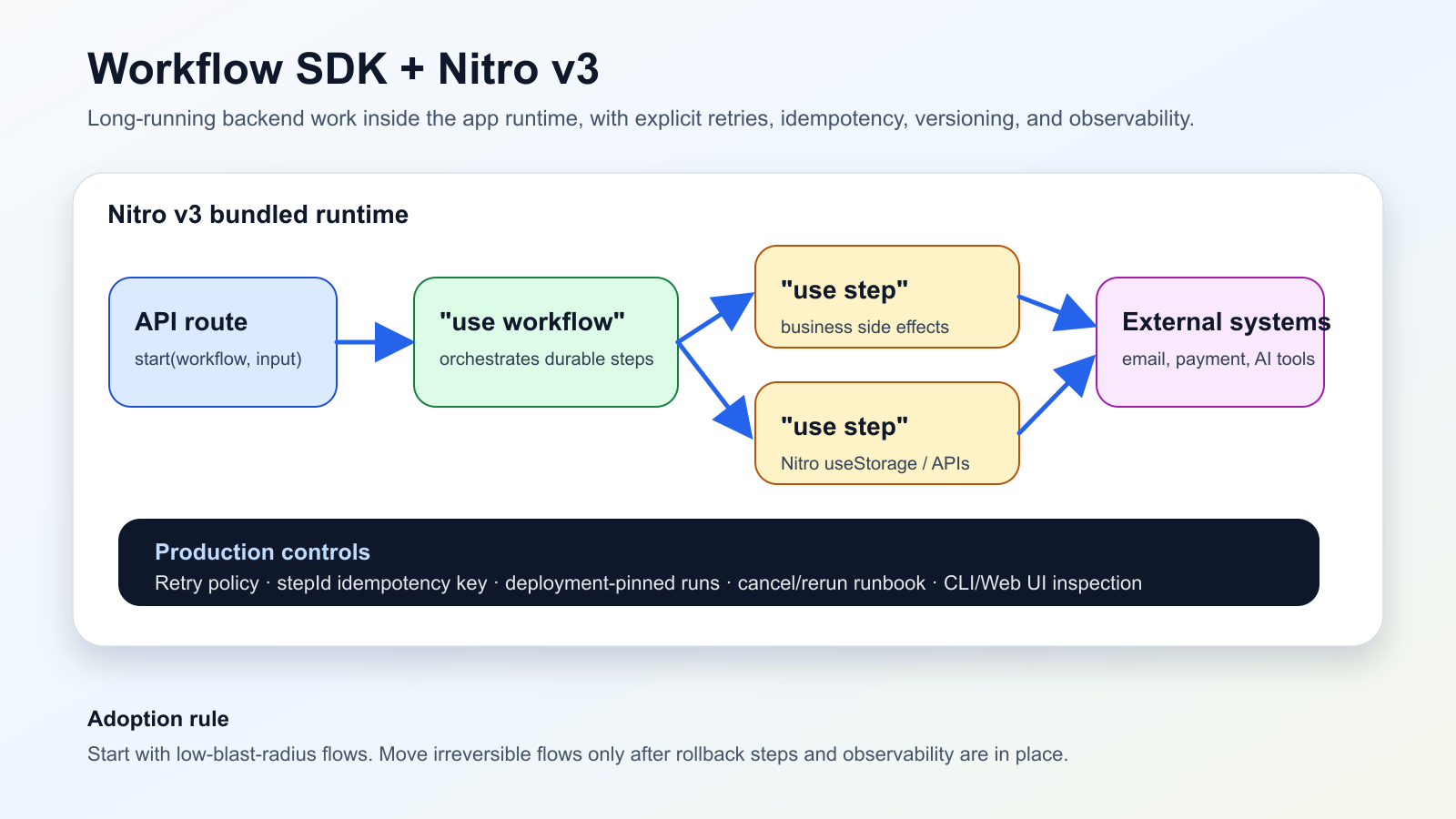
Apa yang terjadi
Pada 13 Juni 2026, Vercel mengumumkan beta integrasi native Workflow SDK untuk Nitro v3. Step berjalan di runtime bundle yang sama dengan aplikasi, route workflow masuk ke build Nitro, dan API server-side seperti useStorage bisa dipakai langsung di fungsi "use step".
Mengapa penting
Bagi tim Nuxt/Nitro, ini mengubah batas antara aplikasi dan worker. Workflow untuk onboarding, laporan, notifikasi tertunda, atau agent yang menunggu persetujuan bisa dimodelkan lebih dekat dengan kode app sebelum dipisah menjadi layanan worker sendiri.
Sinyal komunitas
Namun durable workflow tetap sistem terdistribusi. Retry perlu dikendalikan, side effect harus idempotent, run yang sedang berjalan terikat ke deployment awal, dan observability harus disiapkan sejak hari pertama.
Dampak pengembangan dan operasi
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Checklist praktis
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Risiko dan kontra-argumen
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Sumber
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?