Workflow SDK und Nitro v3: Durable Backends ruecken in die App-Laufzeit
Langlebige Backend-Arbeit entsteht dort, wo ein HTTP-Request nicht reicht: Onboarding, Zahlungen, Berichte, Benachrichtigungen oder Agenten, die auf Freigaben warten. Die native Nitro-v3-Integration des Workflow SDK bringt diese Arbeit naeher an die App.
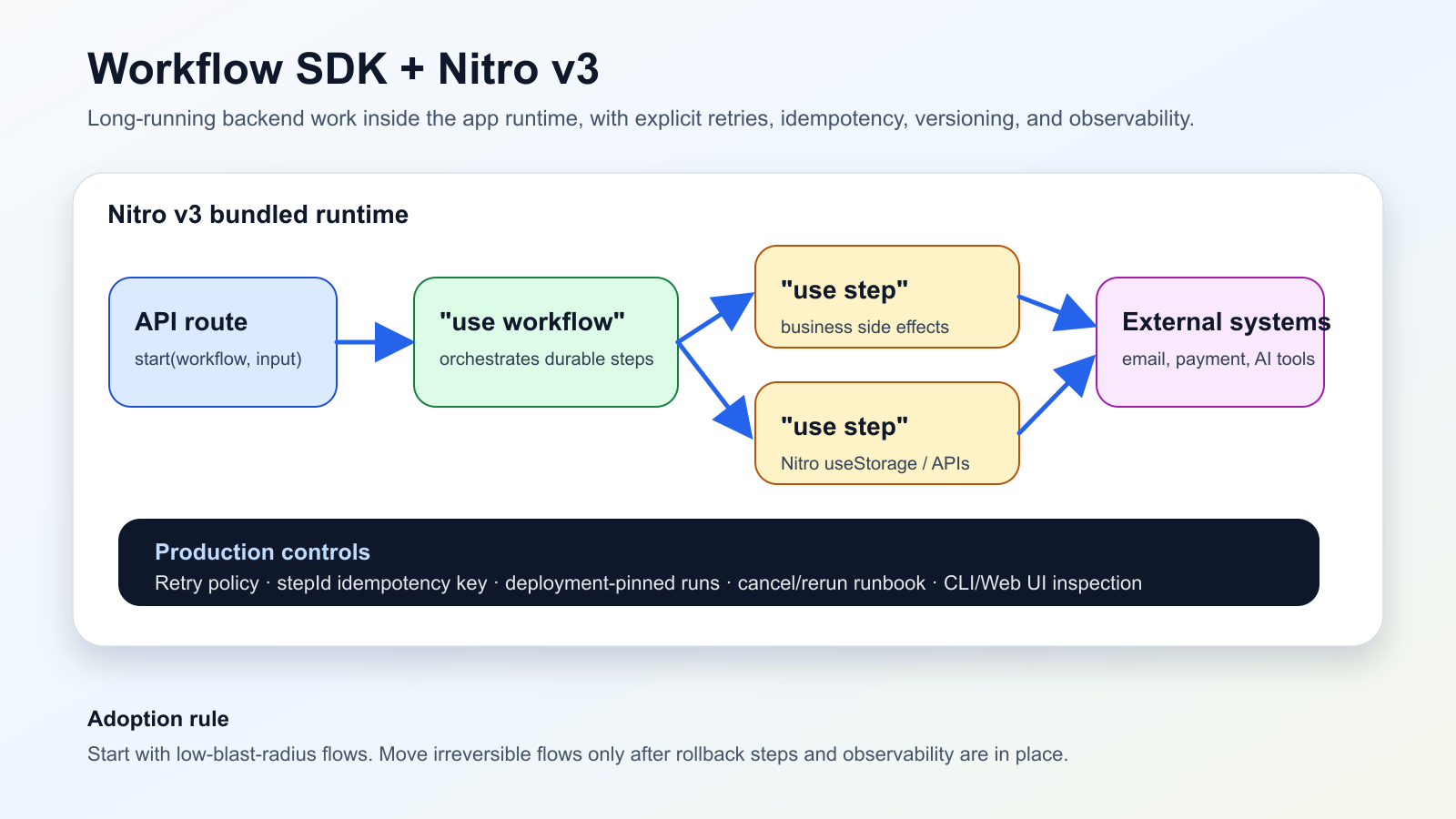
Was passiert ist
Vercel meldete am 13. Juni 2026, dass die Workflow-SDK-Integration fuer Nitro v3 als Beta verfuegbar ist. Steps laufen im selben gebuendelten Runtime-Kontext wie die App, Workflow-Routen werden Teil des Nitro-Builds, und serverseitige Nitro-APIs wie useStorage koennen direkt in "use step"-Funktionen genutzt werden.
Warum es wichtig ist
Fuer Teams mit Nuxt, Nitro oder deployment-agnostischen Servern ist das mehr als Komfort. Es verschiebt langlebige Jobs aus einem separaten Worker-Projekt naeher an die Anwendung. Das reduziert Integrationsaufwand, verlangt aber saubere Regeln fuer Retries, Idempotenz, Deployment-Versionen und Observability.
Signale aus der Community
Die Dokumentation ist hier wichtiger als die Marketingzeile. Steps werden standardmaessig erneut versucht, FatalError trennt absichtliche Fehler ab, RetryableError kann Wartezeiten steuern, und side effects wie Zahlungen oder E-Mails brauchen stabile Idempotenzschluessel. Runs bleiben ausserdem an das Deployment gebunden, in dem sie gestartet wurden.
Auswirkungen auf Entwicklung und Betrieb
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Praktische Checkliste
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Risiken und Gegenargumente
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Quellen
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?