AI Gateway model routing: LLM choice is now an operations policy
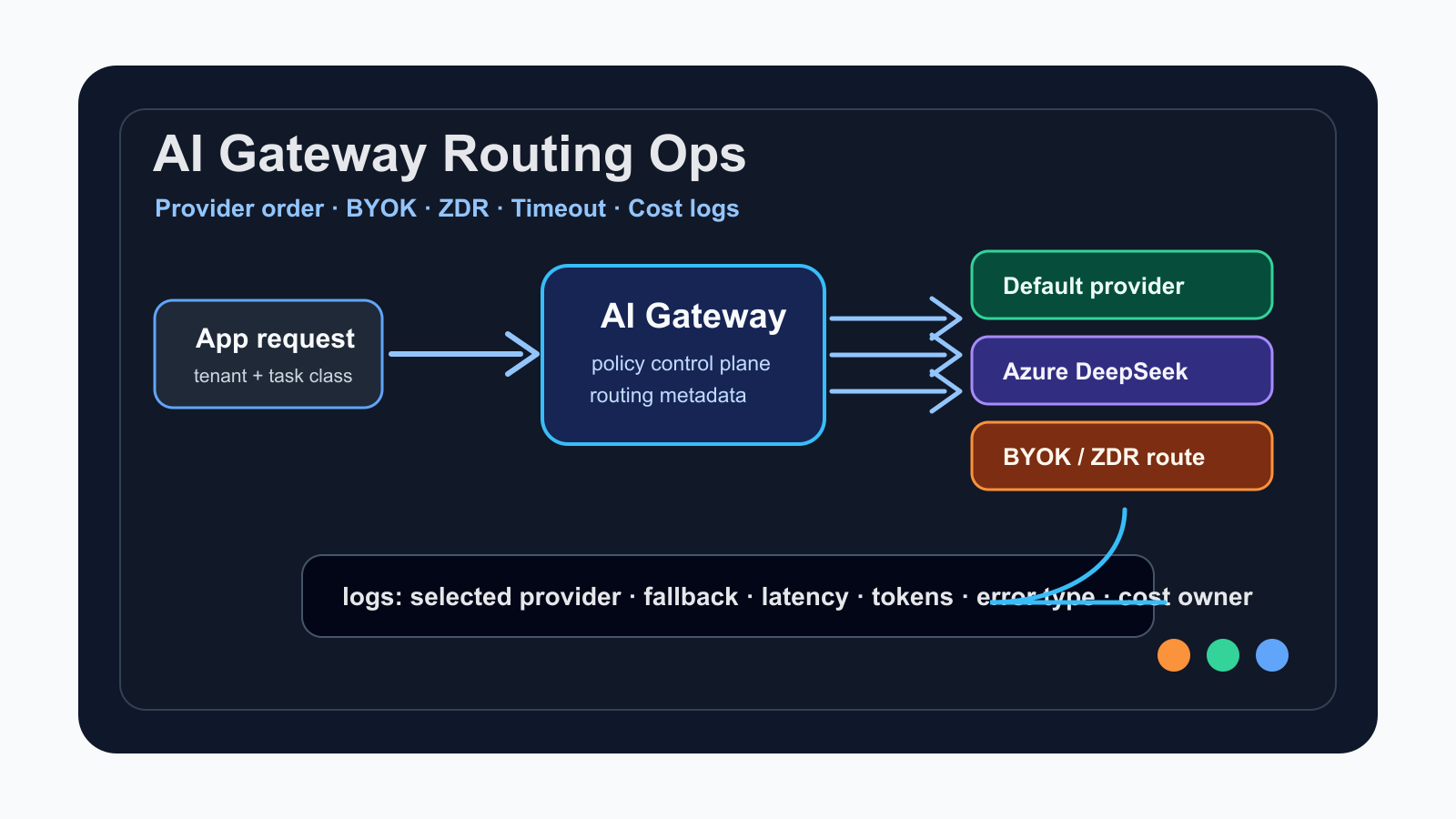
For teams shipping LLM features, the hardest production question is rarely “which model is smartest?” The more common blockers are outages, latency variance, regional provider paths, BYOK agreements, data-retention requirements, and token spend that grows faster than anyone modeled. Model choice is becoming an operations policy, not a one-line SDK decision.
Vercel’s June 11, 2026 AI Gateway update is a useful marker. Azure is now a provider path for DeepSeek V4 Pro and V4 Flash. The interesting part is not just that another route exists. It is that the same model family can be routed through a preferred provider, fall back when a provider fails, and use existing Azure credentials through BYOK.
What happened
The Vercel changelog says AI Gateway can route DeepSeek V4 Pro and V4 Flash requests through Azure alongside existing providers. Default routing considers Azure automatically, and teams can prefer Azure by setting providerOptions.gateway.order in the AI SDK.
That update sits on top of a broader routing surface. Vercel’s Provider Options documentation describes order and only for provider ordering and allow lists. Provider Timeouts can trigger fast failover for slow BYOK providers. The Zero Data Retention documentation explains that sensitive requests can require ZDR-compliant providers and fail when no compliant provider is available.
const result = streamText({
model: 'deepseek/deepseek-v4-pro',
prompt,
providerOptions: {
gateway: {
order: ['azure'],
zeroDataRetention: true,
},
},
});Why it matters
A model string used to look like an implementation detail. In production, each request class has a different service objective. A support-summary request may optimize for cost and latency. A dispute-analysis request may optimize for data retention and auditability. A coding agent may need stable tool calls and long-context behavior. Routing makes those differences explicit.
A gateway layer lets teams move routing, cost, and security decisions out of scattered application branches and into policy. As providers multiply, application code should stay thin while operators gain a surface they can observe and tune. The practical shift is not “DeepSeek is also on Azure”; it is “model-provider choice now needs a deploy-independent control plane.”
Example routing policy by request class
Low-risk summaries
Low-cost default route + short timeout
Cost and latency first
Sensitive data analysis
Force ZDR + restrict allowed providers
Retention policy per request
Enterprise BYOK
Customer or team provider credentials
Clear contract and billing ownership
Realtime UX
Provider timeout + fast fallback
Avoid waiting on a slow provider
Community signals
Developer discussion is already pointing in this direction. In Reddit threads about LLM gateways, practitioners often recommend avoiding early lock-in, starting with a strong default model, and adding multi-model routing once real usage and cost pressure appear. That is not a factual source for product claims, but it is a useful signal of what builders are worried about: lock-in, unpredictable bills, outages, and observability.
The same signal matters for product trust. Users may care less about the exact model name than about whether sensitive data is routed through the right retention policy, whether outages have a fallback, and whether the vendor can explain cost and quality regressions after the fact.
Development and operations impact
For developers, the first impact is architectural: keep model calls thin. If provider order, BYOK credentials, ZDR requirements, timeouts, and tags are scattered across business logic, every model change becomes a source hunt. The second impact is observability. Request class, tenant, selected provider, fallback status, token usage, latency, and error type should be logged from the beginning.
For operations teams, failover is not magic. A timed-out request may still be billed by some providers, and BYOK can move data-retention responsibility back to the direct provider agreement. Treat model routing like CDN routing or database replica routing: it needs a runbook, alerts, rollback criteria, and a quality-review loop.
Practical checklist
• Separate the default model, low-cost fallback, and high-trust fallback by workload type.
• Treat providerOptions.gateway.order and only as environment or tenant policy, not random inline code.
• For BYOK requests, document who owns provider terms, data retention, and billing responsibility.
• Force zeroDataRetention for sensitive prompts and define the product behavior when no provider is available.
• Pair provider timeouts with a total request budget, stream-cancellation expectations, and cost logging.
• Use representative prompts, golden answers, and human-review sampling to catch model-quality regressions.
Risks and counterarguments
The counterargument is real: not every team needs multi-model routing today. If usage is small, prompts are low sensitivity, and one provider gives acceptable quality, a gateway can add complexity before it pays for itself. A cheap fallback without quality checks can also create silent degradation rather than resilience.
The practical conclusion is not “add a gateway everywhere.” It is: once model calls affect reliability, security, or unit economics, prepare to separate routing policy from application code. Start by classifying request types and deciding which ones require cost caps, ZDR, BYOK, provider ordering, or strict fallbacks.