Workflow SDK and Nitro v3: durable backends are moving into the app runtime
The most expensive backend code often lives around work that does not fit inside one HTTP request. A signup flow creates the account, sends a welcome email, waits a few days, and sends onboarding. A payment succeeds but the confirmation response is lost. An AI agent pauses for approval and later resumes tool execution. Those flows pull in queues, schedulers, status tables, retry policies, and observability screens.
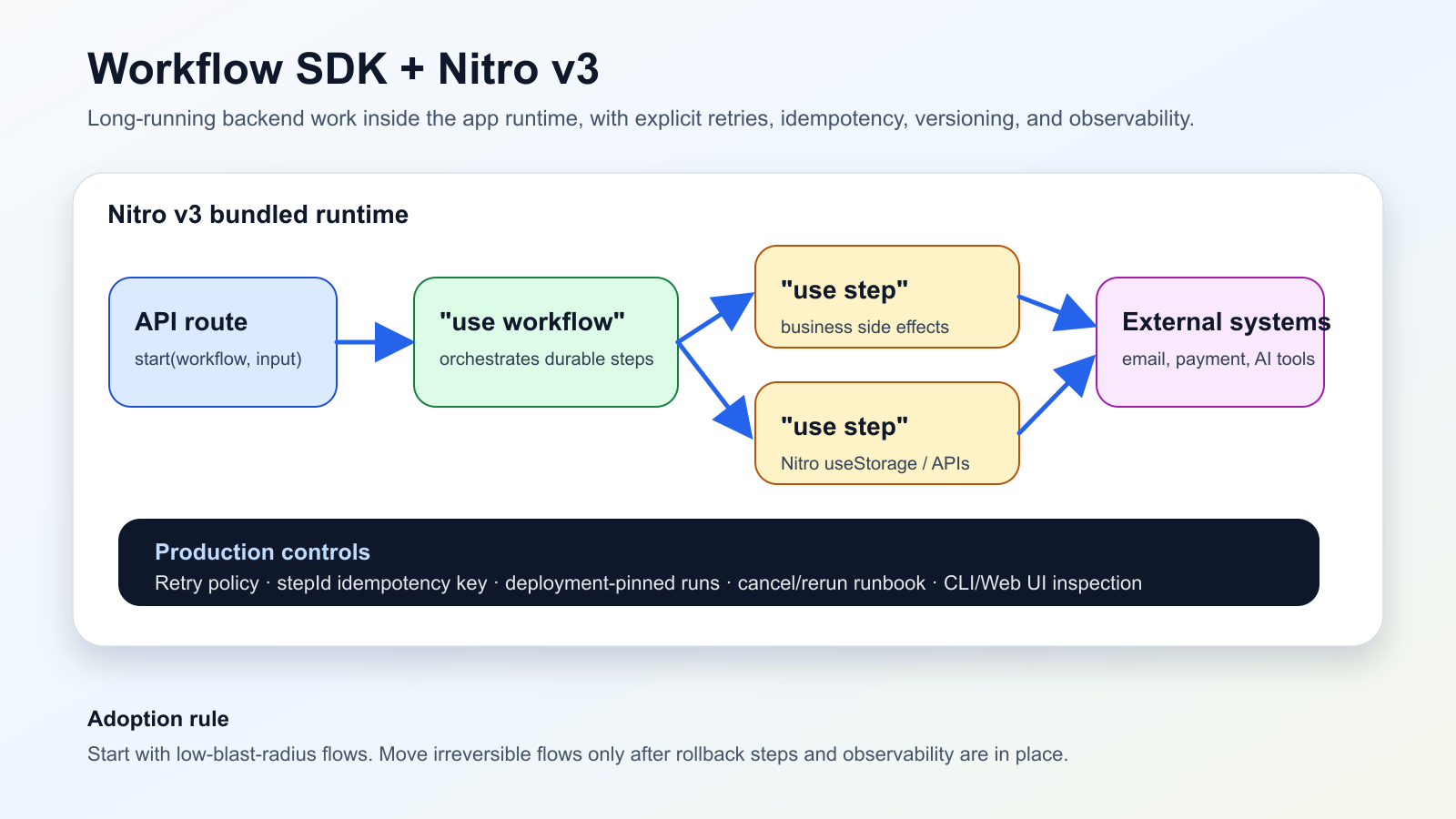
Vercel’s June 13, 2026 changelog entry, “Workflow SDK now runs natively in Nitro v3,” is a meaningful shift for Nuxt and Nitro teams. The beta integration means Workflow SDK steps run inside the same bundled runtime as the rest of the Nitro app rather than a separate bundle. Nitro server-side APIs such as `useStorage()` can be used directly inside `"use step"` functions.
This is not just another SDK announcement. It changes where teams can place long-running backend work, how they reason about retries, and what must be written into the operations runbook before durable workflows become production infrastructure.
What happened
The Vercel changelog says Workflow SDK’s native Nitro v3 integration is now in beta. Workflow routes are bundled as part of the Nitro app build, dependencies are traced, and unused code is tree-shaken so the output includes only what runs. During development, the Nitro server also serves a workflow Web UI at `/_workflow` for inspecting, monitoring, and debugging runs.
The Workflow SDK Nitro guide shows the setup path: add `workflow/nitro` to `nitro.config.ts`, then use `"use workflow"` and `"use step"` directives. A route handler can call `start(handleUserSignup, [email])` to trigger a workflow asynchronously. Inside the workflow, `sleep("5s")` pauses without consuming compute and resumes later. The production section also recommends enabling Fluid compute on Vercel because workflow resumes can otherwise incur separate cold starts.
Why it matters
The change matters because Nitro already positions itself as a deployment-agnostic server runtime. Nitro v3’s site describes a production-ready server layer for Vite apps with deployment targets including Node.js, Cloudflare Workers, Deno, Bun, AWS Lambda, Vercel, and Netlify. Native durable workflows give Nitro teams a way to model long-running backend work closer to the app before splitting out a dedicated worker service.
That changes the boundary. In many stacks, “this needs a queue” quickly becomes “create a separate worker project.” With this integration, an API route can start a workflow, the workflow can orchestrate durable steps, and the steps can call Nitro storage or server APIs directly. The code may become simpler to place, but retries, idempotency, deployment versioning, and observability become first-class application design concerns.
Community signals
Developer communities have been circling the same theme for a while: can durable execution feel like normal async/await? Hacker News discussions around durable TypeScript functions repeatedly bring up checkpointing, replay, and durable promises. That is not a factual source for what Vercel shipped; it is a signal that developers want workflow orchestration to look more like ordinary code than YAML plus worker plumbing.
The caution signal is just as important. A Vercel Community thread about testing Workflows shows that builders are not only asking how to write durable functions, but how to prove they behave correctly. Durable execution is attractive because the code can look simple. It becomes production-ready only when testing, local inspection, retry behavior, and deployment boundaries are explicit.
Development and operations impact
For developers, the immediate impact is structural. The Nitro route handler starts the workflow, a `workflows/` function owns orchestration, and individual steps own side effects. Because those steps live in the app runtime, storage, configuration, and server APIs are easier to reuse. The tradeoff is that step inputs must be serializable and side effects must be safe under retry.
For operations teams, the Workflow SDK documentation is the real checklist. Step errors are retried by default and can be shaped with `maxRetries`, `FatalError`, `RetryableError`, and `retryAfter`. The idempotency guide recommends using stable step IDs as idempotency keys for payments, emails, SMS, queues, and external API writes. The versioning guide explains that runs stay pinned to the deployment that started them, and that moving affected work to fixed code should be an explicit cancel-and-rerun operation.
So the practical meaning is not “background jobs are solved.” It is “the operational rules for long-running work now live closer to app code.” Teams may avoid some worker-service overhead, but they inherit a sharper responsibility to document retries, rollback paths, run inspection, and version boundaries.
Practical checklist
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Risks and counterarguments
The counterargument is straightforward: not every backend task needs a durable workflow. Short cache refreshes, simple webhook forwarding, and operations that users can safely retry may be simpler as ordinary request/response code or a small queue. The Nitro integration is also beta, so production-critical payment, inventory, or compliance notification flows deserve a staged rollout.
Another risk is boundary blur. The fact that a step can call app helpers directly is convenient, but retryable code and non-retryable code must not be mixed casually. Durable workflows are strongest when side effects are isolated, idempotency keys are attached, and compensation steps exist for partial failure. Otherwise the team can create duplicate emails, duplicate external writes, or hard-to-debug resume behavior.
The conservative adoption path is to start with visible, low-blast-radius flows: onboarding email sequences, report generation, delayed notifications, or human-approved AI agent work. Move irreversible flows later, after idempotency, rollback steps, observability, and deployment-version runbooks are boring.
Sources
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?