Workflow SDK и Nitro v3: durable backend переезжает ближе к runtime приложения
Долгие backend-процессы требуют пауз, повторов, состояния и мониторинга. Workflow SDK для Nitro v3 предлагает держать эту оркестрацию ближе к приложению.
Что произошло
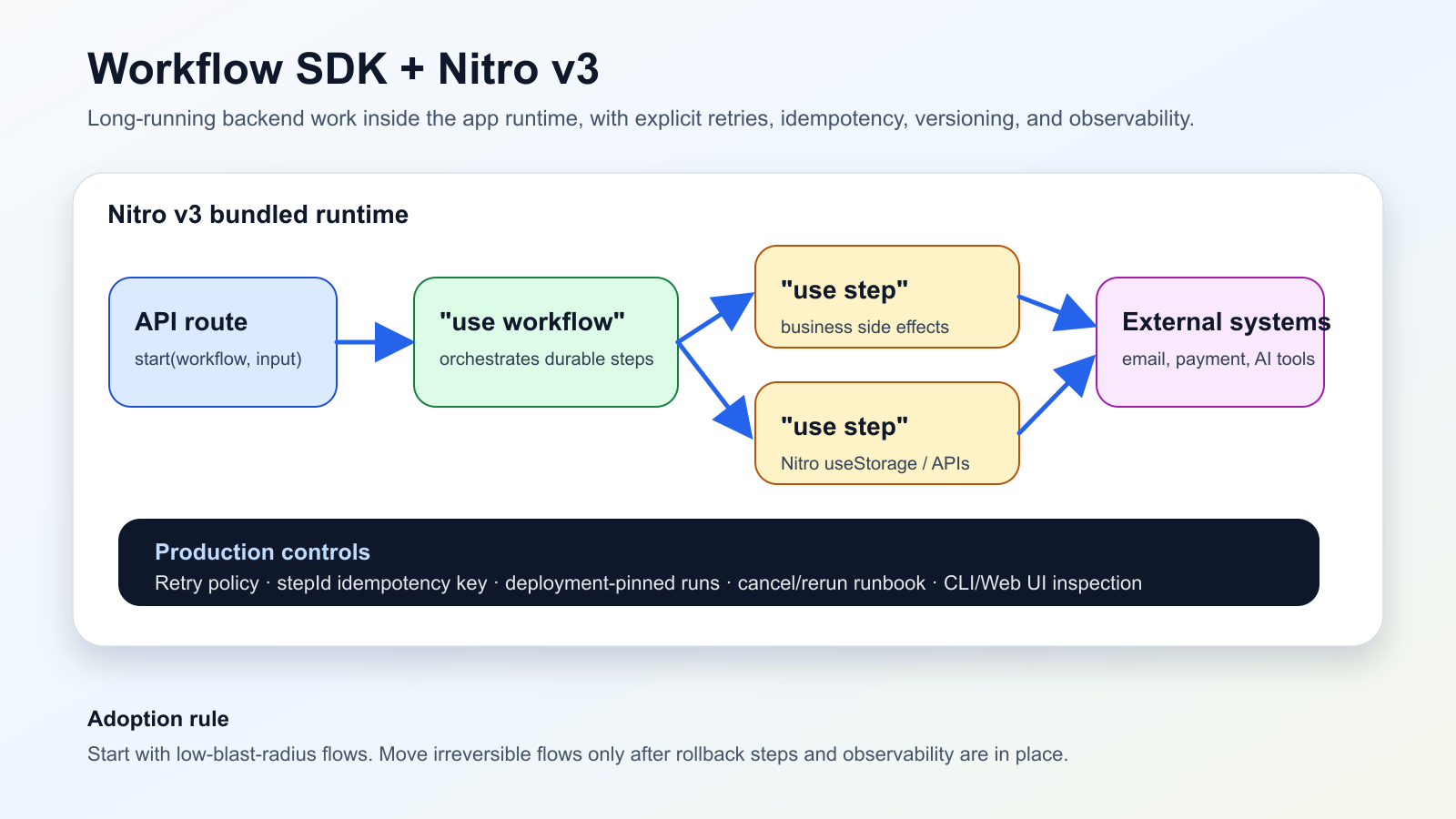
13 июня 2026 года Vercel сообщил о beta-интеграции Workflow SDK с Nitro v3. Steps выполняются в том же bundled runtime, что и приложение, workflow routes входят в Nitro build, а server-side API вроде useStorage можно вызывать внутри "use step".
Почему это важно
Для команд Nuxt/Nitro это меняет место для долгих backend-процессов. API route запускает workflow, "use workflow" оркестрирует шаги, а steps выполняют side effects с ретраями и наблюдаемостью.
Сигналы сообщества
Но durable execution не отменяет дисциплину. Внешние записи должны быть идемпотентны, ошибки нужно делить на fatal и retryable, а in-flight runs остаются привязанными к deployment, который их запустил.
Влияние на разработку и эксплуатацию
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Практический чеклист
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Риски и возражения
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Источники
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?