Workflow SDK e Nitro v3: backends duráveis entram no runtime da aplicação
Fluxos que pausam, retomam ou precisam de retry costumam trazer filas e workers. A integração do Workflow SDK com Nitro v3 torna esse modelo mais próximo do código da aplicação.
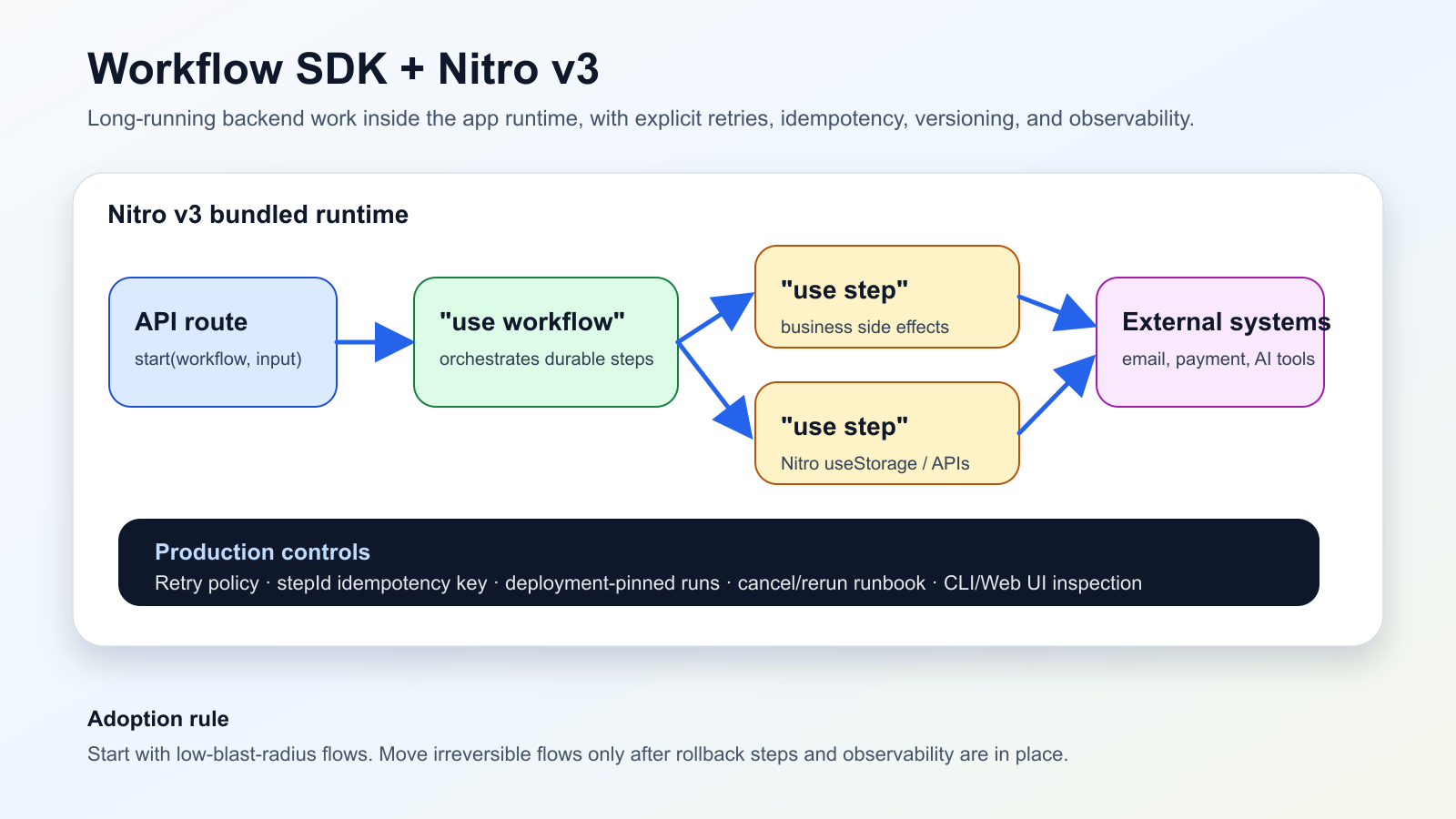
O que aconteceu
Em 13 de junho de 2026, a Vercel anunciou a beta da integração nativa do Workflow SDK com Nitro v3. Os steps rodam no mesmo runtime empacotado da aplicação, as rotas de workflow entram no build do Nitro e APIs como useStorage funcionam diretamente em funções "use step".
Por que importa
Para equipes Nuxt/Nitro, isso muda a fronteira entre app e worker. Fluxos de onboarding, relatórios, notificações atrasadas ou agentes com aprovação humana podem ser modelados perto do código da aplicação antes de virar um serviço separado.
Sinais da comunidade
A parte operacional continua essencial: retries precisam de política, efeitos externos precisam de idempotência, runs em andamento ficam presos ao deployment inicial e a inspeção por CLI/Web UI deve fazer parte do plano.
Impacto em desenvolvimento e operações
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Checklist prática
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Riscos e contrapontos
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Fontes
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?