Workflow SDK ve Nitro v3: durable backend uygulama runtime’ına yaklaşıyor
Tek bir HTTP isteğine sığmayan işler queue, retry, state ve gözlemlenebilirlik ister. Workflow SDK’nın Nitro v3 entegrasyonu bu modeli uygulama koduna yaklaştırıyor.
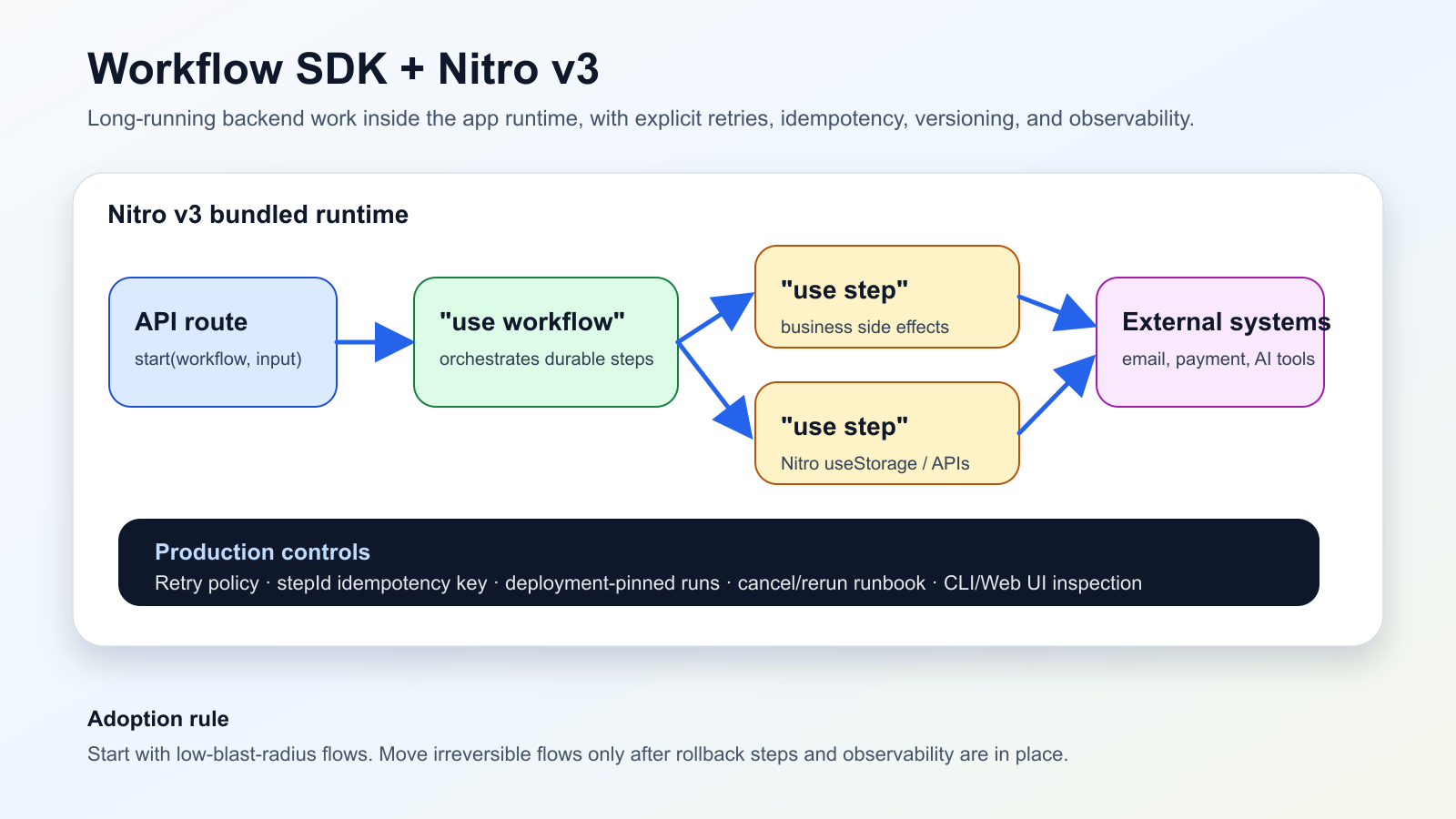
Ne oldu
Vercel, 13 Haziran 2026’da Workflow SDK’nın Nitro v3 ile yerel beta entegrasyonunu duyurdu. Step’ler uygulamanın aynı bundled runtime’ında çalışıyor, workflow route’ları Nitro build’inin parçası oluyor ve useStorage gibi server-side API’ler "use step" içinde kullanılabiliyor.
Neden önemli
Nuxt/Nitro ekipleri için bu, uzun süren backend işlerinin konumunu değiştirir. API route workflow’u başlatır, "use workflow" orchestration yapar, step’ler ise retry edilebilir side effect’leri yürütür.
Topluluk sinyalleri
Operasyon disiplini yine şarttır: dış yazımlar idempotent olmalı, FatalError ve RetryableError ayrılmalı, çalışan run’ların başlangıç deployment’ına bağlı kaldığı bilinmeli ve gözlemlenebilirlik kurulmalıdır.
Geliştirme ve operasyon etkisi
The safest adoption path is incremental. Start with visible, low-blast-radius flows such as onboarding emails, report generation, delayed notifications, or approval-based AI agent work. Move payments, inventory, account deletion, and compliance notifications only after rollback steps and runbooks are boring.
Pratik kontrol listesi
• Classify candidates into work that should finish inside a request, work that needs a queue, and work that needs human intervention.
• Keep the input and output shapes of `"use workflow"` and `"use step"` functions backward-compatible across deployments.
• Attach stable idempotency keys, preferably based on stepId, to payments, emails, external writes, and queue publishes.
• Separate non-retryable validation failures with FatalError and handle rate limits or transient outages with RetryableError plus retryAfter.
• Document how in-flight runs stay pinned to deployments and how affected runs are cancelled or rerun after a fix.
• When steps use Nitro useStorage, server APIs, or route handlers directly, test local and production backend differences.
• Verify that runId, stepId, input class, retry count, failure code, latency, and cost are visible in the CLI or Web UI.
Riskler ve karşı görüşler
This integration is beta, and it is not a reason to rewrite every job. Short cache refreshes and simple webhook forwarding may remain simpler as request/response code or a small queue. The same-runtime convenience should not blur the line between retryable code and code that must never run twice.
Kaynaklar
- Vercel Changelog: Workflow SDK now runs natively in Nitro v3
- Workflow SDK Docs: Nitro pre-release guide
- Workflow SDK Docs: Errors & Retrying
- Workflow SDK Docs: Idempotency
- Workflow SDK Docs: Versioning
- Workflow SDK Docs: Observability
- Nitro v3: Build full-stack servers
- Hacker News discussion signal: Make any TypeScript function durable
- Vercel Community signal: Testing Vercel Workflows?