AI Gateway 모델 라우팅: LLM 선택은 이제 코드가 아니라 운영 정책이다
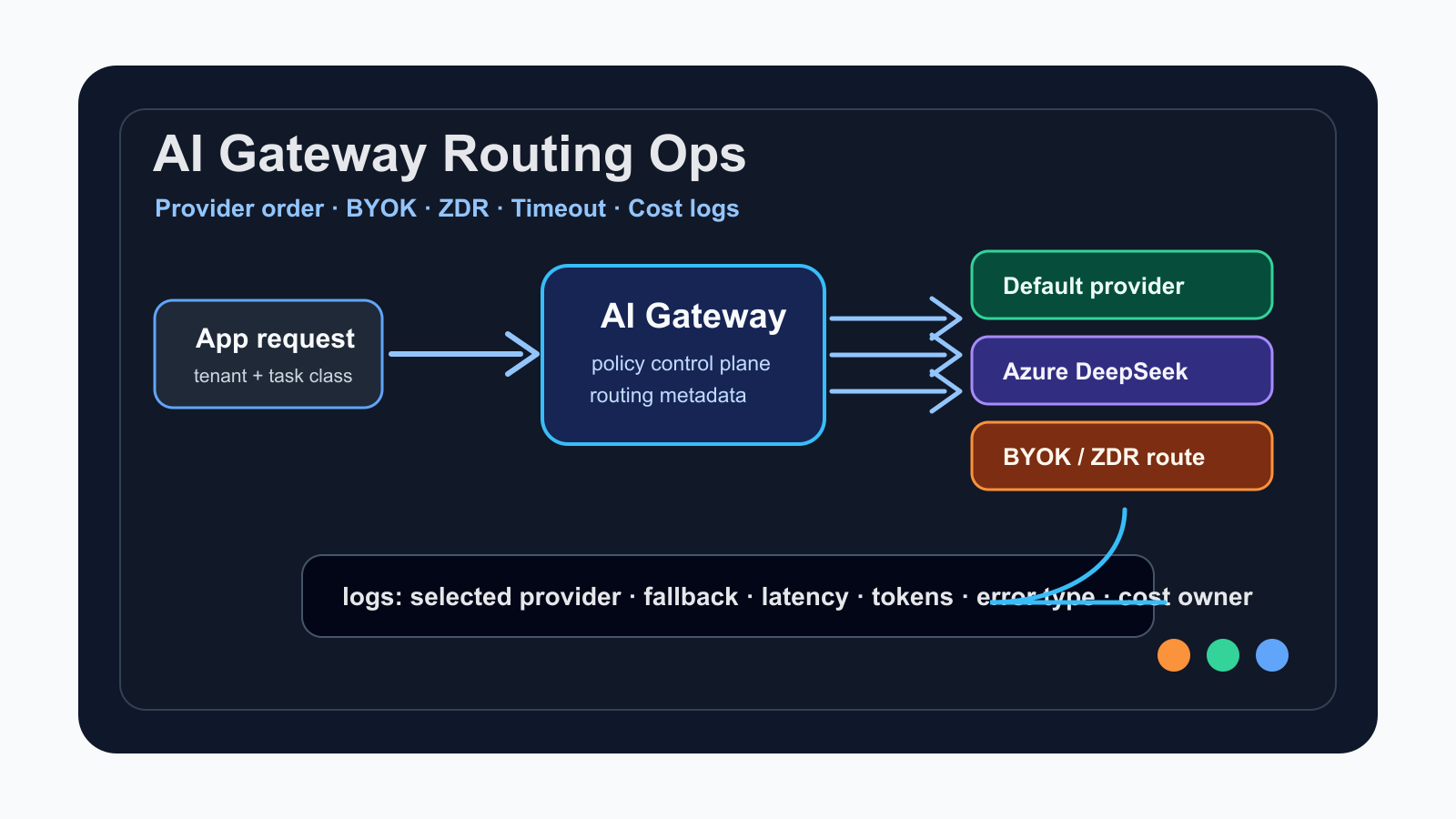
LLM 기능을 제품에 붙인 팀이 가장 자주 부딪히는 문제는 “어느 모델이 제일 똑똑한가”가 아니다. 실제 운영에서는 모델 장애, 지연, 지역별 공급자 차이, BYOK 계약, 데이터 보존 정책, 갑자기 커지는 토큰 비용이 더 먼저 병목이 된다. 그래서 이제 모델 선택은 SDK 한 줄의 문제가 아니라 운영 정책의 문제가 되고 있다.
Vercel이 2026년 6월 11일 AI Gateway에 Azure 경유 DeepSeek V4 Pro와 V4 Flash 라우팅을 추가한 것은 이 흐름을 잘 보여준다. 새 모델 이름이 늘어난 것이 핵심이 아니다. 같은 모델이라도 공급자 경로를 고르고, 장애 시 대체 경로로 넘기고, 기존 Azure 자격 증명을 BYOK로 붙일 수 있다는 점이 개발팀의 아키텍처 선택을 바꾼다.
무슨 일이 있었나
Vercel Changelog에 따르면 Azure는 DeepSeek V4 Pro와 V4 Flash의 AI Gateway 공급자로 추가됐다. 기본 라우팅에서는 AI Gateway가 기존 공급자들과 함께 Azure 경로를 고려하며, 공급자 장애가 발생하면 남은 목록으로 fallback할 수 있다. 특정 요청에서 Azure를 먼저 시도하고 싶다면 AI SDK의 providerOptions.gateway.order에 azure를 지정하는 식으로 라우팅 순서를 제어할 수 있다.
이 업데이트는 AI Gateway 문서가 설명하는 더 큰 기능 세트 위에 올라간다. Provider Options는 order와 only로 공급자 순서와 허용 목록을 조정하게 해 주고, Provider Timeouts는 BYOK 자격 증명에 대해 느린 공급자를 빠르게 포기하고 다음 공급자로 넘어가게 한다. Zero Data Retention 문서는 민감한 요청에서 ZDR 공급자만 쓰도록 강제할 수 있으며, 가능한 공급자가 없으면 오류가 난다고 명시한다.
const result = streamText({
model: 'deepseek/deepseek-v4-pro',
prompt,
providerOptions: {
gateway: {
order: ['azure'],
zeroDataRetention: true,
},
},
});왜 중요한가
프론트엔드나 백엔드 코드에서 model: "provider/model" 문자열만 바꾸던 시대에는 모델 운영이 간단해 보였다. 하지만 프로덕션 트래픽이 생기면 같은 기능도 요청 유형에 따라 다른 SLA를 가진다. 고객 지원 요약은 비용과 지연이 중요하고, 결제 분쟁 분석은 데이터 보존과 감사 로그가 중요하며, 코드 생성 에이전트는 도구 호출 안정성과 긴 컨텍스트 유지가 중요하다.
AI Gateway 같은 라우팅 계층은 이 차이를 코드 분기 대신 정책으로 다룰 수 있게 한다. 모델 공급자가 늘어날수록 애플리케이션 코드는 단순해야 하고, 라우팅·비용·보안 판단은 운영자가 관찰하고 조정할 수 있어야 한다. 이것이 이번 소식의 실무적 의미다. “DeepSeek를 Azure에서도 쓸 수 있다”보다 “모델 공급자 선택을 배포 없이 바꾸는 운영면이 필요해졌다”가 더 큰 변화다.
요청 유형별 라우팅 정책 예시
저위험 요약
저비용 기본 경로 + 짧은 timeout
비용과 응답속도가 우선
민감 데이터 분석
ZDR 강제 + 허용 공급자 제한
보존 정책을 요청 단위로 보장
엔터프라이즈 BYOK
고객 또는 팀별 provider credentials
계약·과금 책임을 명확히 분리
실시간 UX
provider timeout + 즉시 fallback
느린 공급자 대기를 줄임
커뮤니티 신호
개발자 커뮤니티에서는 이미 “처음부터 단일 공급자에 묶이지 말라”, “초기에는 강한 기본 모델을 쓰되 실제 비용 압력이 생기면 라우팅을 고도화하라”는 식의 의견이 반복된다. Reddit의 AI Gateway 논의는 엄밀한 사실 근거가 아니라 현장의 불안과 우선순위를 보여주는 신호로 읽어야 한다. 사람들은 성능보다도 lock-in, 비용 예측, 장애 대응, 관측성을 묻고 있다.
이 신호는 제품팀에도 중요하다. 사용자에게는 “우리는 모델 A를 씁니다”보다 “민감한 데이터는 ZDR 경로로 제한하고, 장애 시 대체 경로를 쓰며, 비용 상한과 사용량 로그를 가지고 있습니다”가 더 설득력 있는 설명이 될 수 있다. AI 기능이 보조 기능을 넘어 핵심 워크플로가 될수록 라우팅 정책은 제품 신뢰의 일부가 된다.
개발·운영 영향
개발 영향은 첫째, 모델 호출부를 얇게 유지해야 한다는 점이다. provider order, BYOK, ZDR, timeout, tags 같은 값이 비즈니스 로직 곳곳에 흩어지면 모델 교체가 아니라 코드 archaeology가 된다. 둘째, 관측성 필드를 처음부터 넣어야 한다. 요청 유형, tenant, selected provider, fallback 여부, token usage, latency, error type을 기록하지 않으면 나중에 비용이나 품질을 설명할 수 없다.
운영 영향은 더 직접적이다. failover가 있다고 해서 비용이 줄거나 품질이 보장되는 것은 아니다. timeout으로 끊은 요청도 공급자에 따라 과금될 수 있고, BYOK는 데이터 보존 책임을 Gateway가 아니라 사용 중인 공급자 계약으로 옮길 수 있다. 따라서 운영팀은 모델 라우팅을 CDN routing이나 database replica routing처럼 runbook, alert, rollback 기준을 가진 인프라로 봐야 한다.
팀이 바로 점검할 체크리스트
• 기본 모델, 저비용 대체 모델, 고신뢰 대체 모델을 작업 유형별로 나눈다.
• providerOptions.gateway.order와 only를 코드가 아니라 환경·테넌트 정책으로 관리한다.
• BYOK를 쓰는 요청은 공급자 약관, 데이터 보존, 과금 책임이 어디로 이동하는지 문서화한다.
• ZDR가 필요한 프롬프트에는 zeroDataRetention을 강제하고 실패 시 사용자 경험을 정의한다.
• provider timeout은 재시도 폭탄이 되지 않도록 전체 요청 예산, 스트리밍 취소, 비용 로그와 함께 본다.
• 모델별 품질 회귀를 잡기 위해 대표 프롬프트 세트, golden answer, human review 샘플링을 둔다.
리스크와 반론
반론도 있다. 모든 팀이 멀티 모델 라우팅을 지금 당장 도입할 필요는 없다. 사용량이 작고 민감 데이터가 없고 한 공급자 품질이 충분하다면 Gateway 계층은 비용과 복잡도를 늘릴 수 있다. 특히 품질 검증 없이 저렴한 fallback만 추가하면 사용자는 더 빠른 실패 대신 더 조용한 품질 저하를 겪을 수 있다.
따라서 실무 결론은 “게이트웨이를 무조건 넣자”가 아니다. 결론은 “모델 호출이 제품의 안정성, 비용, 보안 책임과 연결되는 순간 라우팅 정책을 코드 바깥으로 분리할 준비를 하자”다. 지금 할 일은 공급자 수를 늘리는 것이 아니라 요청 유형을 분류하고, 어떤 요청에 어떤 데이터 보존·비용·지연 기준이 필요한지 정하는 것이다.